Large-scale visuomotor policy learning is a promising approach toward developing generalizable manipulation systems. Yet, policies that can be deployed on diverse embodiments, environments, and observational modalities remain elusive.
In this work, we investigate how knowledge from large-scale visual data of the world may be used to address one axis of variation for generalizable manipulation: observational viewpoint.
Specifically, we study single-image novel view synthesis models, which learn 3D-aware scene-level priors by rendering images of the same scene from alternate camera viewpoints given a single input image.
For practical application to diverse robotic data, these models must operate zero-shot, performing view synthesis on unseen tasks and environments.
We empirically analyze view synthesis models within a simple data-augmentation scheme that we call View Synthesis Augmentation (VISTA) to understand their capabilities for learning viewpoint-invariant policies from single-viewpoint demonstration data.
Upon evaluating the robustness of policies trained with our method to out-of-distribution camera viewpoints, we find that they outperform baselines in both simulated and real-world manipulation tasks.
Method Overview
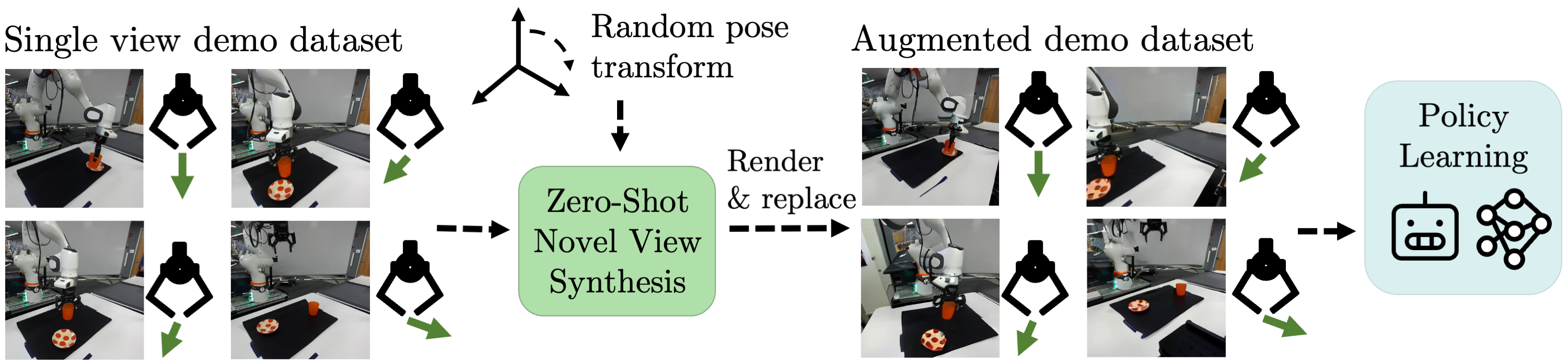
Our key insight is that view synthesis models that have been trained on large scale, diverse data may provide useful 3D priors for visuomotor robotic policy learning.
We focus on an imitation learning setting, in which the VISTA framework generates augmented demonstrations by rendering images of the same scene from alternate camera viewpoints given a single input image. These synthesized images are paired with the same actions as the original images, allowing for viewpoint-robust policy training.
Example Augmented Dataset Trajectories
Below, we show examples of expert demonstration trajectories augmented by various novel view synthesis models. For ZeroNVS (finetuned), the model is finetuned on synthetic data from MimicGen tasks for simulated environments and on the DROID dataset for the real setting, qualitatively improving the fidelity of generated images and quantitatively improving downstream policy performance.
Please see the manuscript and appendix for more details about finetuning.
Qualitative Behavior of
Learned Policies on Novel Test Viewpoints
Here we show rollouts of policies trained with view synthesis model augmentation when placed in random test viewpoints on the quarter circle arc distribution. We note that even when the policies augmented using the finetuned ZeroNVS model fails, they tend to make more progress on the task compared to single view or depth estimation and reprojection baselines. Critically, note that these policies are all trained using a single-view source demonstration dataset. Real-world videos are at 6x speed.
Learning & Deploying View-Invariant Policies on Real Robots
Using the ZeroNVS novel view synthesis model, we learn diffusion policies that take as input both third-person and (unaugmented) wrist camera observations to solve a "put cup in saucer" task from multiple novel viewpoints. Again, the original training dataset only contains trajectories observed from a single RGB view.
We find that performance is further improved by finetuning the ZeroNVS model on the DROID dataset.
Successful rollouts (6x speed) from policies trained on datasets augmented by a pretrained ZeroNVS model and a ZeroNVS model finetuned on DROID data. The visualized viewpoint is the viewpoint of the observation provided to the policy.
In contrast, a baseline model trained on the single original view and wrist observations is heavily overfitted to the original view, and often fails to reach toward the cup when tested on novel views:
Original Viewpoint (6x)
Novel Viewpoint (6x)
Novel Viewpoint (6x)
Additionally, we find that policies that are trained on only wrist observations can have difficulty localizing the correct object to grasp (in this case the cup). Note that here the third-person view is only for visualization and is not provided to the policy. Videos are at 6x speed:
Acknowledgements
We thank Hanh Nguyen and Patrick "Tree" Miller for their help with the real robot experiments, and Weiyu Liu, Kyle Hsu, Hong-Xing "Koven" Yu, Chen Geng, Ruohan Zhang, Josiah Wong, Chen Wang, Wenlong Huang, and the SVL PAIR group for helpful discussions. This work is in part supported by the Toyota Research Institute (TRI), NSF RI #2211258, and ONR MURI N00014-22-1-2740. ST is supported by NSF GRFP Grant No. DGE-1656518.
BibTeX
@article{tian2024vista,
title = {View-Invariant Policy Learning via Zero-Shot Novel View Synthesis},
author = {Stephen Tian and Blake Wulfe and Kyle Sargent and Katherine Liu and Sergey Zakharov and Vitor Guizilini and Jiajun Wu},
year = {2024},
journal = {arXiv}
}