Are These the Same Apple?
Comparing Images Based on Object Intrinsics
Klemen Kotar*, Stephen Tian*, Hong-Xing “Koven” Yu, Daniel L.K. Yamins, Jiajun Wu
* indicates equal contribution.
Stanford University
NeurIPS 2023 Datasets and Benchmarks Track
The human visual system can effortlessly recognize an object under different extrinsic factors such as lighting, object poses, and background, yet current computer vision systems often struggle with these variations. An important step to understanding and improving artificial vision systems is to measure image similarity purely based on intrinsic object properties that define object identity. The problem has been studied in the computer vision literature as re-identification, though mostly restricted to specific object categories such as people and cars. We propose to extend it to general object categories, exploring an image similarity metric based on object intrinsics.
To benchmark such measurements, we collect the Common paired objects Under differenT Extrinsics (CUTE) dataset of 18,000 images of 180 objects under different extrinsic factors such as lighting, poses, and imaging conditions.
While existing methods such as LPIPS and CLIP scores do not measure object intrinsics well, we find that combining deep features learned from contrastive self-supervised learning with foreground filtering is a simple yet effective approach to approximating the similarity. We conduct an extensive survey of pre-trained features and foreground extraction methods to arrive at a strong baseline that best measures intrinsic object-centric image similarity among current methods.
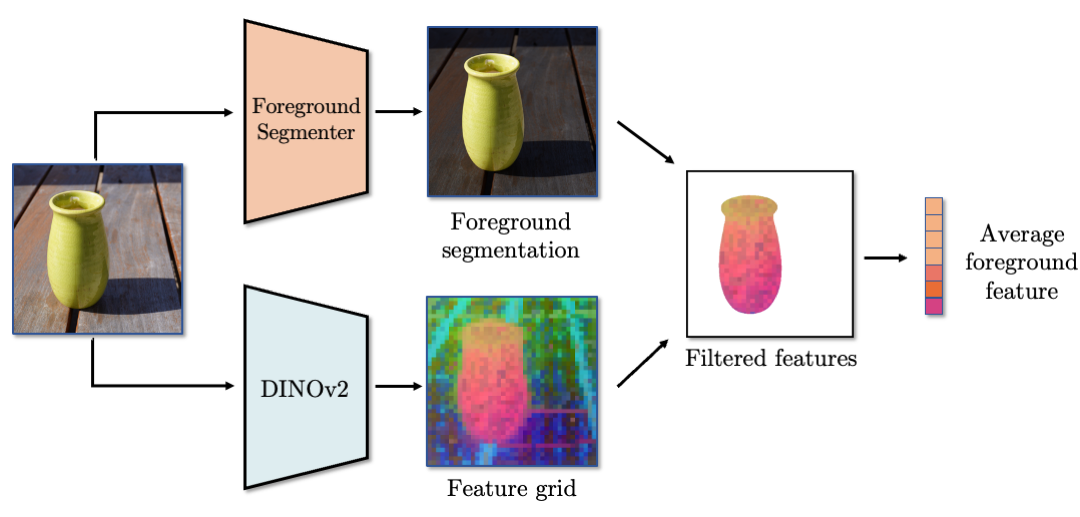
This approach, which we call foreground feature averaging (FFA), combines a generalizable pre-trained deep feature backbone with foreground filtering and patch-level feature pooling.
An overview of the model is shown below:
CUTE Dataset
Benchmarking intrinsic object similarity metrics in a systematic way requires images of slightly different objects with the same semantics, combined with varying extrinsics. Existing object-centric datasets that have similar objects do not capture the same objects with varying poses or lighting conditions. Datasets that contain objects with these factors of variations, such as multi-view photometric stereo datasets, do not have sufficiently similar objects within a single category. This motivates us to collect a new dataset, Common paired objects Under differenT Extrinsics (CUTE).
Our dataset is composed of object instances from each of 50 semantic object categories. Objects belonging to a particular semantic category have differences such as shape or texture that identify them as distinct objects. For example, the category “apples” contains apples with distinct shapes and textures. The dataset contains a total of $180$ objects. These categories range from items such as fruits like “apples”, “oranges”, to household items like “plates” and “forks”. Examples of the objects in the dataset are shown in Figure 3, and a full list of object categories can be found in supplementary material. Of the $50$ object categories, $10$ categories contain ten object instances, while all other categories contain two object instances.
For each of the $180$ objects, we consider three types of extrinsic configurations: different illumination, different object poses, and in-the-wild captures.
Example Data
































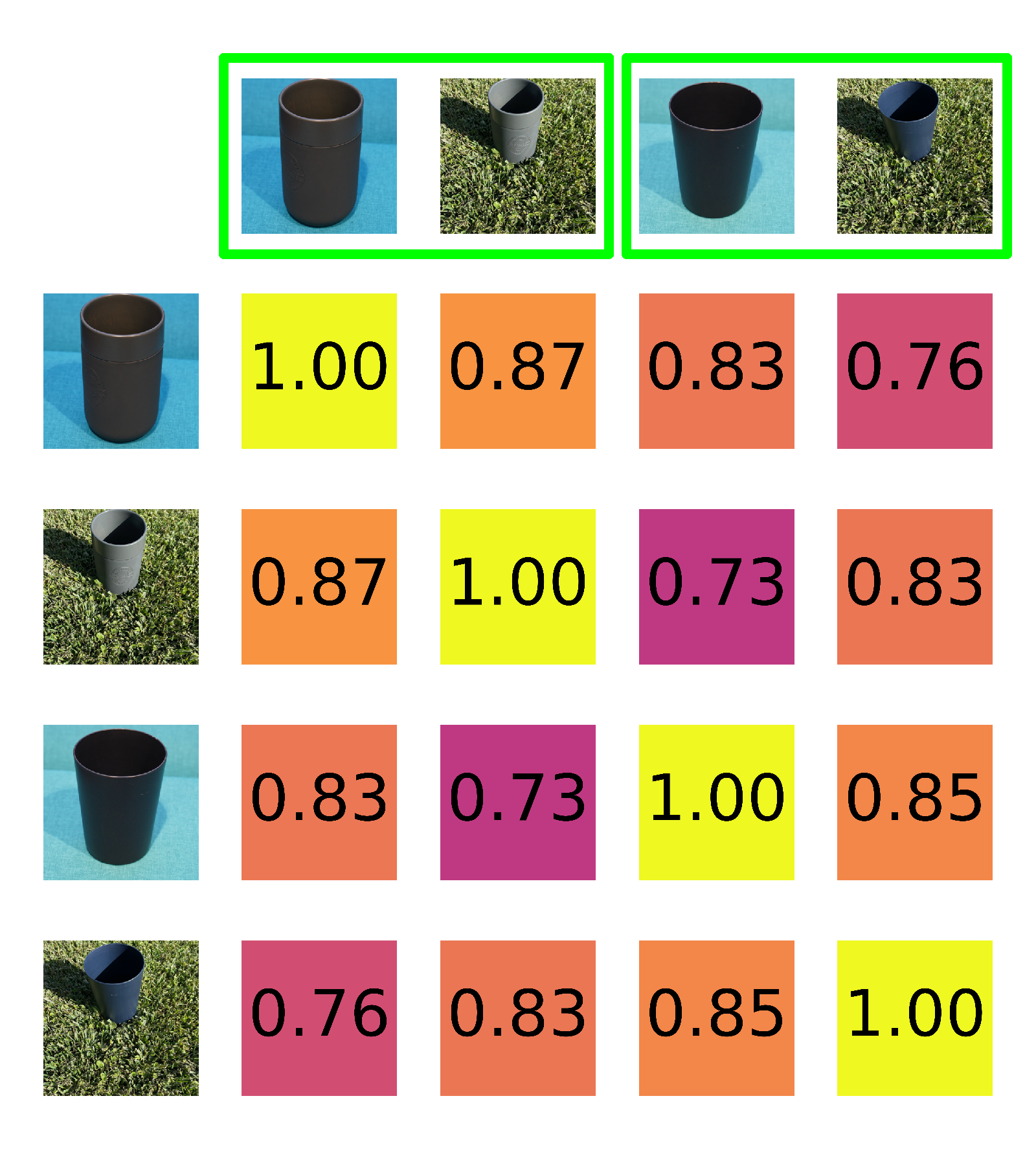
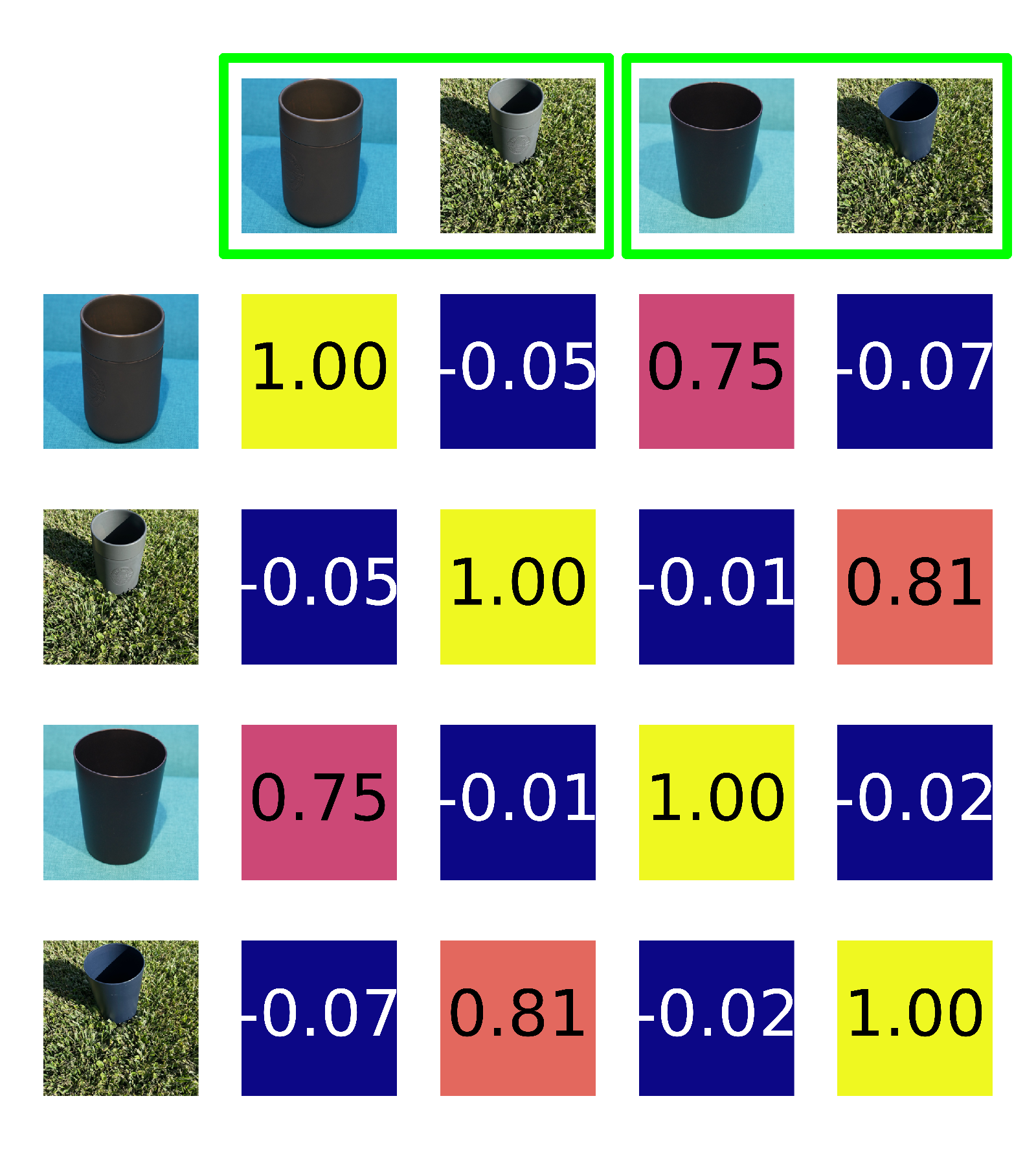
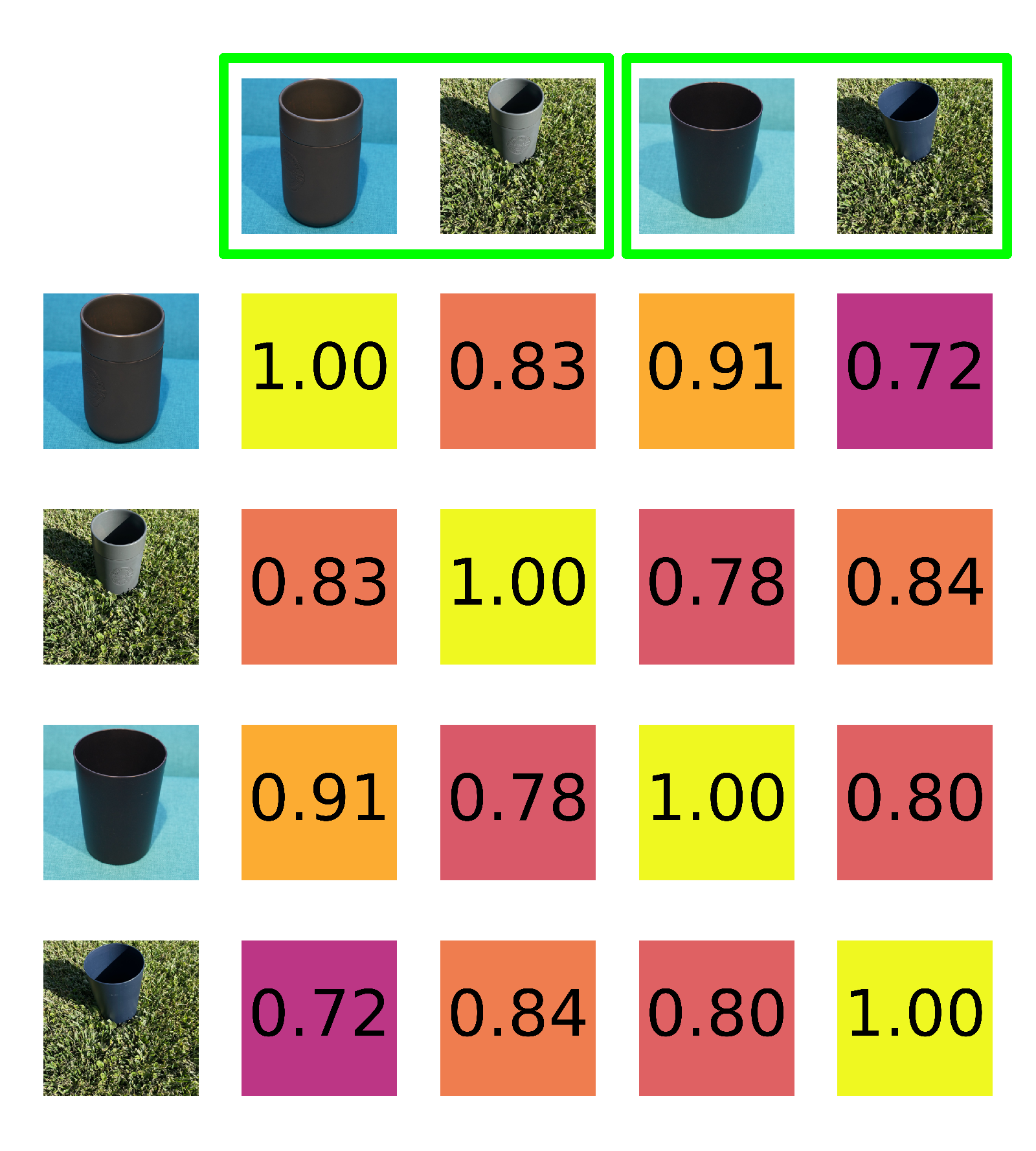
Qualitative results examples
In these examples, we plot the pairwise similarity between our images from each group. Images in green frames contain the same object instances. An ideal intrinsic object similarity measure would score all values in the upper left and lower right quadrants of each grid, which are comparisons between the same objects, most highly (closer to $1$). We find that the FFA metric displays this behavior, while LPIPS and CLIPScore do not. The displayed images are cropped for better visibility in this visualization only.






Dataset Sample
Here we show random samples from the entire dataset:






























BibTeX
@inproceedings{kotar2023cute,
title={Are These the Same Apple? Comparing Images Based on Object Intrinsics},
author={Klemen Kotar and Stephen Tian and Hong-Xing Yu and Daniel L.K. Yamins and Jiajun Wu},
journal={Neural Information Processing Systems Datasets and Benchmarks Track},
year={2023}
}